

Synergy is the Future
On the topic of code, no-code, and configuration-based solutions

There’s been a lot of discussion lately around code, no-code, and what the future might look like with these types of solutions in the data industry. If you haven’t yet read Tristan’s roundup or Sarah’s post, I highly encourage you do to so. They’re both great reads and are exactly what I’ll be talking about in this post.
Why are we having these discussions? Why do we care?
It seems inevitable that both code and no-code solutions will always exist, but is there a future where a symbiotic mutualistic relationship between the two exists?
If you ask any engineer whether they’d prefer a no-code solution over a coded one, the answer is almost unanimously for code, and it’s easy to understand why. The primary consequences of using no-code solutions are antithetical to the workflows and principles of an engineering organization:
they lack version control, pull requests, diffs, reviews,
they create chaos in both governance and democratization,
they don’t play well with others (e.g. vendor lock-in),
they don’t lend themselves towards interoperability.
Despite these drawbacks, there are numerous benefits that we can realize from no/low-code solutions. Namely, they reduce the barrier to participation in technical workflows — they enable a wider, non-technical audience to contribute not only where they were previously unable to do so, but also in ways they were previously unable to — and ideally, those ways need to directly integrate with engineering processes and best practices.
So what do we need to think about in building these solutions to ensure they seamlessly integrate with engineering workflows? There’s a particular excerpt from Tristan’s post that aims to define what the requirements of a combined code & no-code solution might look like.
Here are what I believe the requirements of a great no-code solution to be:
No-code systems actually have to, behind the scenes, write code. They have to anticipate that there will be two main modalities: code written by their tools, and code written by hand. Both modalities must be a part of the experience of using the product, even if the product itself doesn’t contain a code editor. The language ergonomics are a part of the product.)
No-code products must store their resulting code as a files in a filesystem. git, CI/CD, PRs, and all developer automation rely on code living in files, not traditional data stores that one would typically build a SaaS product on top of.
No-code products must integrate with git providers as the primary source of truth for the current state of the codebase.
Code-written-by-humans and code-written-by-no-code-tools have to be able to live side-by-side in the same repo sensibly. Better yet, human- and system-written code should be interchangeably edited by the other modality (cannot be “one-way”).
Code written by the no-code experience has to be readable by humans so that PRs can be meaningfully reviewed.
His proposal directly addresses the negative symptoms of no-code solutions, particularly from the engineering point of view. So if we’re able to craft a hybrid solution that realizes all of the benefits of no-code solutions while eliminating the disadvantages from an engineering perspective, we then need to think about who the actors in these hybrid systems are, their capabilities, and the areas of our data workflows it makes sense to build these solutions for.
1 Shift. 2 Shift. Redshift. Blueshift.
If you’re reading this, chances are you’re probably familiar with the concept of purple in the data industry. When we talk about purple, it’s usually in the context of people — who purple people are — what characteristics and traits they embody, their capabilities of working across the business and engineering aisles. But we don’t really talk about purple in the context of participation and enablement.
If you think about the color spectrum in this way, and about the tools dbt Labs provides analysts in applying engineering best practices to analytical workflows, they’ve essentially enabled analysts to blueshift on the spectrum towards blue, making themselves more purple, or, as I will henceforth call it, purpleshifting — the act of making one’s self more purple, regardless of where you fall on the spectrum.

There was, however, a common shared language between analysts and engineering that truly enabled this shift — SQL. Where dbt acted as the medium, SQL was the language that powered the transformation. I know there are many out there who both desire and envision a future where everyone is data-literate — and data literacy means proficiency in SQL and (at least) a basic understanding of how to work with data. While that may be ideal, it’s not exactly realistic and certainly won’t help us in the meantime or the near-future.
Similar to the shift that analysts have undergone, I believe the the future no-code experiences will enable business users to purpleshift and participate in the analytics process (in areas where it makes sense).

While no-code experiences may be the medium to enable interaction and participation, we still need a shared language to communicate with to make this a truly transformative shift that scales — and that language must be instrumental to the analytical workflow. That language can’t be SQL because it’s unreasonable to expect everyone to learn it. Enter YAML.
YAML Ain’t Markup Language
We’ve all been so busy talking about the future of code vs. no-code solutions, we’ve neglected to define what we actually consider code. We know that both SQL and python are programming languages (code). But Markdown and HTML aren’t — they’re markup languages. What about YAML? It’s data serialization language — it’s a data format that represents a way of structuring or serializing data and enables you to read and write arbitrary data.
But I don’t think any of this really matters — it’s not about code vs. no-code or what we consider to be code. What we’re really after is a language that’s shared across humans and directly integrates with the data stack. I think that language is YAML. It was designed to be human-readable and it helps to power some of the most important parts of our data stacks and analytical workflows. And while it’s useful for a breadth of programming needs, it’s primarily used as a configuration language and format in the modern data stack. Configuration formats are designed specifically to assist human operators — end users shouldn’t have to worry about underlying processes or accepted data types — they should be able to operate on the surface level without needing to understand the inner workings behind the scenes. And while it may not be feasible for everyone to learn and communicate with SQL, I do think it’s reasonable to carve a path to a future where everyone is able to use and communicate with YAML as a configuration language.
YAML not only satisfies the requirements for our shared language, but it also operates in the spaces that actually make sense for non-technical users to interact with, particularly in the areas of metadata management and the metrics layer.
Persona-wise, different non-technical roles will interact with different areas. An executive or VP level person might want to explore metrics and try creating their own. A PM might be concerned with overall metadata management — models, columns, descriptions, tags, etc. A test engineer would be focused on tests. Data ops on observability metadata. There’s a whole spectrum of metrics and metadata where less technical folks could operate.
SQL may be the how, but YAML is the what — and the what is informed by requirements, which are informed by the business. It directly influences the outputs of the data teams — the things that are ultimately consumed by the business itself. So by enabling business participation in a way that modifies YAML, we’re enabling them to directly shape and contribute to the outputs that they themselves consume. Not only does this promote greater synergy amongst the teams, it also frees up engineering resources to work on the more challenging problems that are fundamental to how data is produced.
What does this future look like?
There’s a particular bullet I want to highlight from Tristan’s excerpt:
Code-written-by-humans and code-written-by-no-code-tools have to be able to live side-by-side in the same repo sensibly. Better yet, human- and system-written code should be interchangeably edited by the other modality (cannot be “one-way”).
I think we can take this one level further. While this does enable us to have additional avenues for contributing to code, I’m not convinced it ultimately lends itself to speed, efficiency, or scale from the business user’s perspective, nor does it really contribute to a shared understanding. In order to achieve those, we’d need to break free from user interfaces and write actual code, or YAML configuration in this case.
You might be thinking, “doesn’t this put us back to square one with both code and no-code solutions?” Yeah, it kind of does…unless we can create a truly hybrid experience of these solutions.
When Tristan says these tools “have to be able to live side-by-side in the same repo,” I think we should take live side-by-side quite literally — in the user interface.

For the non-technical side to scale their contributions, we need to promote proficiency in YAML. The best way to do that is to show them what actually happens behind the scenes when they use a no-code interface. We need to show them, in real-time, exactly how their interactions in the UI impact the configuration (YAML) that’s used to help power their workflows. Over time, they should become comfortable with the patterns and structures they see, and ultimately, they’ll be able break free from the user interface itself and instead directly write YAML. These two modalities should live side-by-side, and should reflect each other in real-time. Still, there may be some concerns with this paradigm.
In Sarah’s Configuration as Code example, she’s right when she says:
There is no UI today to replace all the functionality YAML provides. Developing a UI to replace a configuration language is a tall order.
But I don’t think we need to replace all the functionality YAML provides. We only really need to focus on developing user interfaces that work within the constraints of pre-defined structures, which are essentially the schemas of all the YAML-based artifacts that business users would be interested in working with. In doing so, we lower the bar of YAML-competency required, and we narrow the scope these tools need to operate in. We’re not giving them a blank slate — we’re giving them a focused, structured modality to interact with, within a (business) context they’re already familiar with.
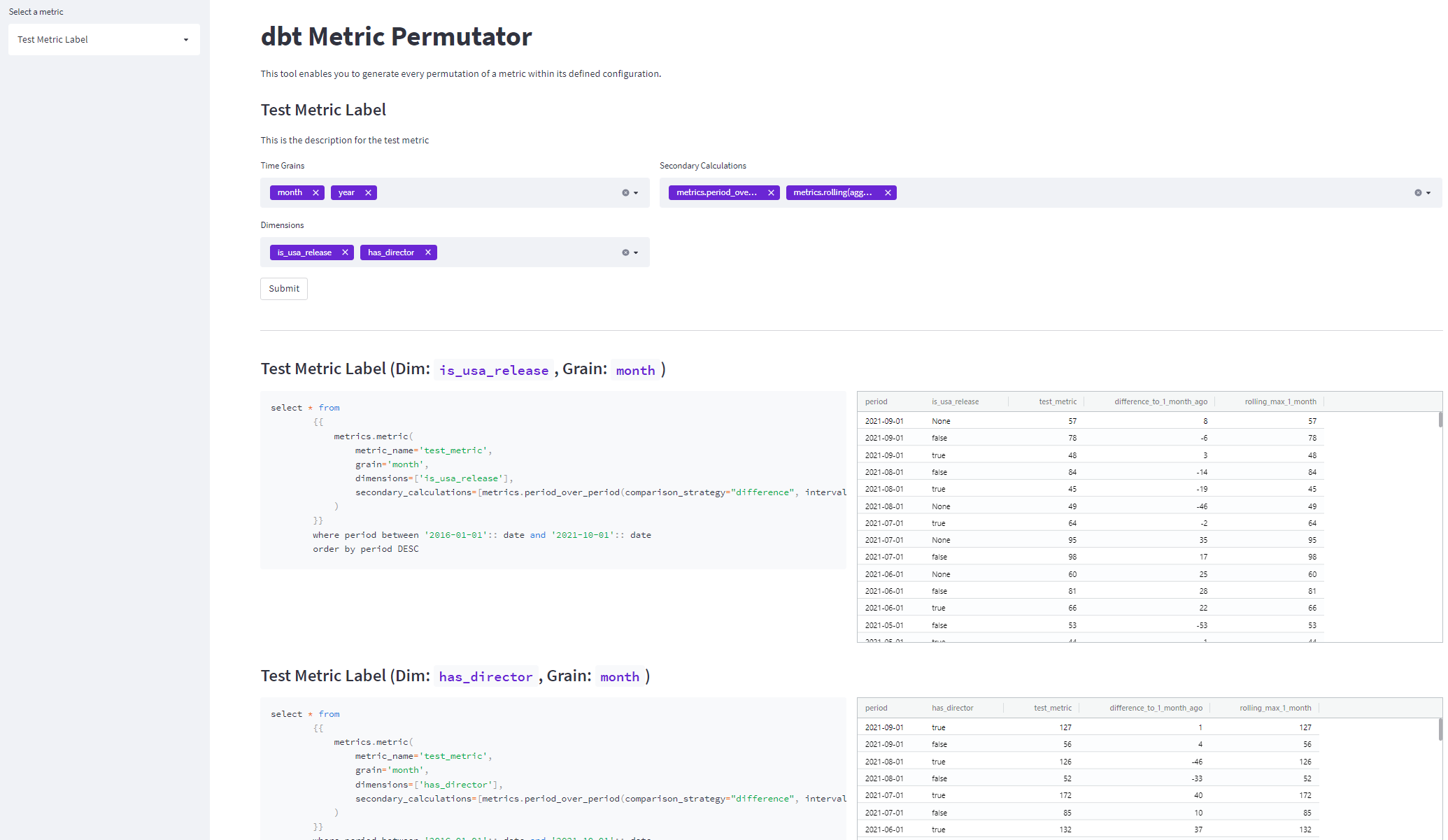
We shouldn’t stop here though. It’s not enough to just show users what the UI inputs translate to as code — we need to tie it all together. We need to help them understand how the changes in the code or configuration impact the downstream outputs they consume, which is where a tight integration with version control and a live preview environment, like Netlify’s Deploy Previews, would be needed.
In practice, we could have something like the below, which was generated off of the metric configuration in the previous screenshot.

At this point, we have:
enabled business users to directly contribute to their own consumptions,
provided two accessible modalities (UI and configuration) to enable this participation,
shown the direct outputs and implications of their changes,
provided a sandbox for them to play around with different configurations,
all within a live preview environment that simply enables them to ask, “what if it was like this?” without the fear of actually breaking something downstream.
What then follows is providing a way for users to say, “yes, I like this and want it in production,” or, “no, I don’t actually want this, let’s scrap it.” This is again where the tight integrations with version control and CI/CD come into play. If the user wants to see this in production, they should be able to click a button that says, “Submit for review” — which then automatically creates a pull request in the version control system. Similarly, they should be able to discard their changes and continue experimenting.
But wait, there’s more!
While I do believe the purpose of these future experiences should be to help purpleshift everyone towards a more purple future and enable participation across the spectrum, at the same time, we can also help us, help ourselves. In reality, these future experiences we’ve been describing are really just data apps that focus on providing multiple methods of interacting with the codebase. These data apps shouldn’t be limited to the YAML configuration — they can also help us write the actual code, explore the results of what we do, and so, so much more.
Disclaimer - any opinions expressed are solely my own and do not express the views or opinions of my employer.